

Já tentou ensinar um truque novo ao seu cachorro usando um petisco como recompensa? Esse simples ato de premiar um comportamento desejado é a base de um dos campos mais poderosos e transformadores da Inteligência Artificial: a Aprendizagem por Reforço (Reinforcement Learning - RL).

Diferente do aprendizado supervisionado, que depende de gigantescos conjuntos de dados rotulados, o RL adota uma abordagem radicalmente distinta. Aqui, a IA se torna um agente autônomo, um explorador digital lançado em um ambiente para aprender por conta própria. Seu único guia? Um sistema de recompensas e punições. Através de pura tentativa e erro, ele aprende a navegar, a jogar e a otimizar, descobrindo estratégias que nenhum humano jamais programou explicitamente. É a ciência de criar IAs que aprendem a "vencer o jogo" — seja ele qual for.
Como a IA Aprende Sozinha? Os Pilares do Reinforcement Learning
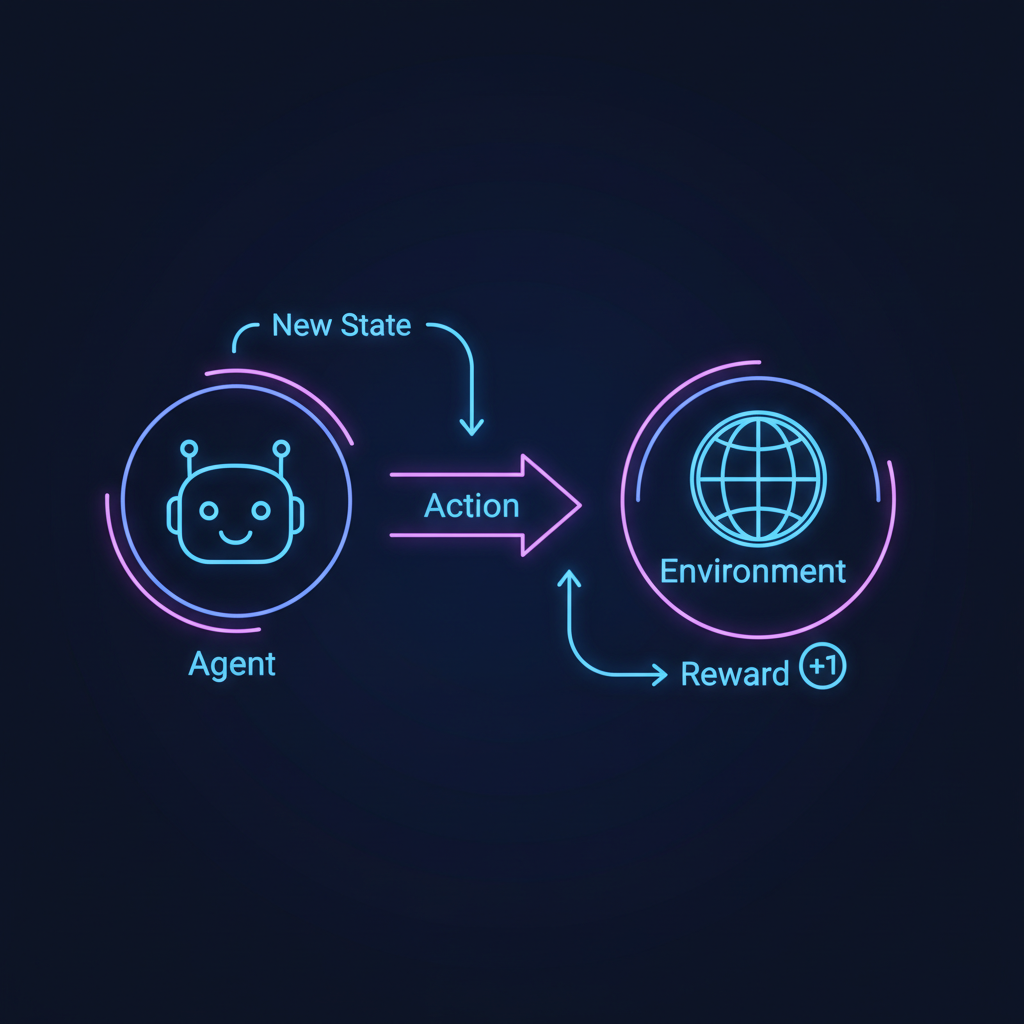
Para que um agente de IA possa aprender sozinho, ele precisa interagir com seu mundo através de um conjunto bem definido de regras e componentes. Imagine um robô aprendendo a navegar em um labirinto complexo. Os elementos em jogo são:
- Agente: O nosso robô. É a entidade que observa, decide e age. Pode ser um algoritmo de negociação no mercado de ações, um braço robótico em uma linha de montagem ou o cérebro controlando um personagem em um jogo.
- Ambiente: O labirinto em si — o universo onde o agente existe. Ele define as regras do jogo, as paredes, os caminhos e o objetivo final. O ambiente reage às ações do agente e determina as consequências.
- Estado (State): Uma "foto" instantânea do ambiente. Para o robô, seu estado é sua localização exata (coordenadas X, Y) e talvez a proximidade das paredes. Para um Carro Autônomo, o estado incluiria sua velocidade, posição, e a localização de outros veículos.
- Ação (Action): O repertório de movimentos que o agente pode executar em um dado estado. Para o robô, as ações poderiam ser: "avançar", "virar à esquerda", "virar à direita" ou "parar".
- Recompensa (Reward): O feedback crucial que o ambiente fornece após uma ação. É o "petisco" digital. O robô pode receber uma grande recompensa positiva (+100) ao achar a saída, uma pequena punição negativa (-1) por cada passo dado (para incentivá-lo a ser eficiente) e uma grande punição negativa (-50) se colidir com uma parede.
- Política (Policy): A estratégia ou o "cérebro" do agente. É a função que mapeia um estado a uma ação. No início, a política é aleatória (o robô se move sem rumo). O objetivo de todo o treinamento em RL é refinar essa política para que ela sempre escolha a ação que maximiza a recompensa total esperada a longo prazo.
O Loop Infinito: Observar, Agir e Aprender
O processo de RL é um ciclo dinâmico e contínuo: o agente observa o estado atual, consulta sua política para escolher uma ação, executa essa ação no ambiente, e recebe de volta uma recompensa (ou punição) e o novo estado. Esse ciclo se repete milhares ou milhões de vezes, permitindo que o agente, gradualmente, construa uma política cada vez mais sofisticada e eficaz.
O Dilema do Agente: Explorar o Novo ou Explorar o Conhecido?
No coração do aprendizado está o dilema da exploração vs. explotação (exploration vs. exploitation). O agente deve "explotar" (aproveitar) o caminho que já conhece e que lhe rende uma recompensa garantida? Ou deve "explorar" novos caminhos, arriscando-se a encontrar becos sem saída, mas também com a chance de descobrir um atalho para uma recompensa muito maior?
É o mesmo dilema que enfrentamos ao escolher entre ir ao nosso restaurante favorito (explotar uma boa experiência conhecida) ou experimentar um novo lugar que pode ser decepcionante ou surpreendentemente melhor (explorar). Um agente de RL eficaz precisa equilibrar de forma inteligente essas duas estratégias para não ficar preso em uma solução meramente "boa" e garantir que encontre a melhor solução possível.
Da Teoria à Prática: Onde a Aprendizagem por Reforço Já Transforma o Mundo
A Aprendizagem por Reforço já deixou de ser um conceito puramente acadêmico e hoje alimenta algumas das tecnologias mais avançadas do nosso tempo.
Games e Estratégia Sobre-Humana
A DeepMind, do Google, chocou o mundo com o AlphaGo, a IA que derrotou os melhores jogadores humanos de Go, um jogo de tabuleiro com mais configurações possíveis do que átomos no universo observável. O AlphaGo aprendeu jogando contra si mesmo, descobrindo estratégias que séculos de análise humana não haviam concebido. O mesmo princípio foi aplicado para dominar games complexos como StarCraft II e Dota 2.
Robótica Autônoma e Adaptativa
Robôs em centros de distribuição usam RL para aprender a pegar objetos de formas e tamanhos variados, uma tarefa extremamente difícil de programar manualmente. Empresas como a Boston Dynamics treinam robôs quadrúpedes para andar, correr e se adaptar a terrenos acidentados, recuperando-se de tropeços de forma autônoma e fluida.
Otimização de Sistemas Complexos
O RL é a força por trás da otimização em larga escala. Ele é usado para gerenciar a alocação de recursos em data centers do Google (reduzindo os custos de energia em até 40%), otimizar o fluxo de tráfego em cidades inteligentes e personalizar sistemas de recomendação (Netflix, YouTube), que aprendem dinamicamente qual conteúdo sugerir para maximizar seu engajamento e satisfação.
A Aprendizagem por Reforço é a primeira teoria computacional de como agentes podem otimizar seu controle sobre um ambiente de forma eficiente. Richard S. Sutton, um dos pioneiros da área
Por Dentro do Código: Como um Agente de RL "Pensa"
O Algoritmo em Ação: Pseudocódigo
Para materializar o ciclo de aprendizado, veja este pseudocódigo que ilustra o loop de treinamento de um agente. Ele mostra a "conversa" contínua entre o agente e seu ambiente para refinar a política de decisão.
# Loop principal de treinamento, executado por múltiplos "episódios"
# (um episódio é uma tentativa completa, como uma partida de um jogo)
para cada episódio:
# Reseta o ambiente para o estado inicial
estado_atual = ambiente.reset()
partida_terminou = falso
enquanto não partida_terminou:
# 1. ESCOLHA DA AÇÃO: O agente usa sua política atual para decidir
# o que fazer com base no estado que está observando.
acao_escolhida = agente.escolher_acao(estado_atual)
# 2. INTERAÇÃO COM O AMBIENTE: A ação é executada no mundo.
# O ambiente responde com o resultado.
novo_estado, recompensa, partida_terminou = ambiente.executar(acao_escolhida)
# 3. APRENDIZADO: O agente analisa a transição
# (estado_atual, acao_escolhida, recompensa, novo_estado)
# e atualiza sua política para tomar decisões melhores no futuro.
agente.aprender(estado_atual, acao_escolhida, recompensa, novo_estado)
# 4. TRANSIÇÃO: O agente "se move" para o novo estado.
estado_atual = novo_estado
Exemplo Prático com Python e Gymnasium
Para quem deseja experimentar, bibliotecas como Stable Baselines3 e ambientes de simulação como o Gymnasium (sucessor do OpenAI Gym) são ferramentas incríveis. O código abaixo treina um agente simples para resolver o ambiente "FrozenLake", onde ele deve atravessar um lago congelado sem cair nos buracos.
# pip install gymnasium stable-baselines3
import gymnasium as gym
from stable_baselines3 import PPO
# 1. Cria o ambiente (o "mundo" do agente)
env = gym.make("FrozenLake-v1", is_slippery=False)
# 2. Define o modelo de RL (PPO é um algoritmo popular e robusto)
model = PPO("MlpPolicy", env, verbose=0)
# 3. Treina o agente
# O agente irá "jogar" 10.000 vezes para aprender a política ótima
model.learn(total_timesteps=10000)
# 4. Avalia o agente treinado
obs, info = env.reset()
for _ in range(100):
action, _states = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
print(f"Objetivo alcançado com recompensa: {reward}")
obs, info = env.reset()
break
env.close()
Desafios e o Futuro Autônomo da IA
Apesar de seu poder, a Aprendizagem por Reforço enfrenta desafios significativos, como a ineficiência de amostragem (a necessidade de milhões de tentativas para aprender tarefas complexas) e a dificuldade em projetar funções de recompensa que não levem a comportamentos indesejados (o chamado "reward hacking").
Mesmo assim, o RL está pavimentando o caminho para uma nova geração de sistemas inteligentes. Não se trata mais de máquinas que apenas seguem instruções pré-programadas, mas de agentes que aprendem, se adaptam e resolvem problemas de maneiras criativas e eficientes. Ao dominar a arte de aprender com as consequências de suas próprias ações, a IA está dando um passo fundamental em direção a uma autonomia genuína e à solução de desafios que hoje parecem intransponíveis.





0 Comentários