


Se você já explorou o universo da ciência de dados ou acompanhou competições como as do Kaggle, provavelmente já ouviu falar de um campeão recorrente: o Gradient Boosting. Mas o que torna esse algoritmo tão especial? Não se trata de uma fórmula mágica, mas de uma estratégia brilhante que transforma modelos "fracos" em um time de especialistas coeso e de altíssima performance.
Neste post, vamos desvendar como o Gradient Boosting funciona, por que ele é tão eficaz e como você pode começar a usá-lo para elevar o nível dos seus próprios projetos de machine learning.
O que é Gradient Boosting? Construindo um Especialista a Partir dos Erros
Imagine que você precisa montar uma equipe para prever o preço de imóveis. Em vez de buscar um único analista genial, você adota uma abordagem incremental:
- Você contrata um primeiro analista. Ele faz uma previsão inicial, mas naturalmente comete alguns erros.
- Em vez de descartá-lo, você analisa exatamente onde e quanto ele errou.
- Então, você contrata um segundo especialista com uma única missão: prever e corrigir os erros do primeiro.
- Um terceiro especialista é contratado para corrigir os erros residuais da dupla, e assim por diante.
O Gradient Boosting opera com essa mesma lógica. É uma técnica de ensemble learning do tipo boosting, que constrói modelos de forma sequencial e aditiva. Cada novo modelo é treinado para corrigir as falhas — ou, mais tecnicamente, os resíduos — do conjunto de modelos anteriores. O resultado final não é um único modelo, mas um comitê robusto de "modelos fracos" (geralmente árvores de decisão rasas) que, juntos, formam um único "modelo forte" com um poder de previsão notável.
O Mecanismo por Trás do Gradient Boosting
O processo é iterativo e focado em melhoria contínua. A genialidade está em fazer com que cada novo membro da "equipe" se concentre nos exemplos mais difíceis, que são justamente aqueles em que os modelos anteriores mais erraram.
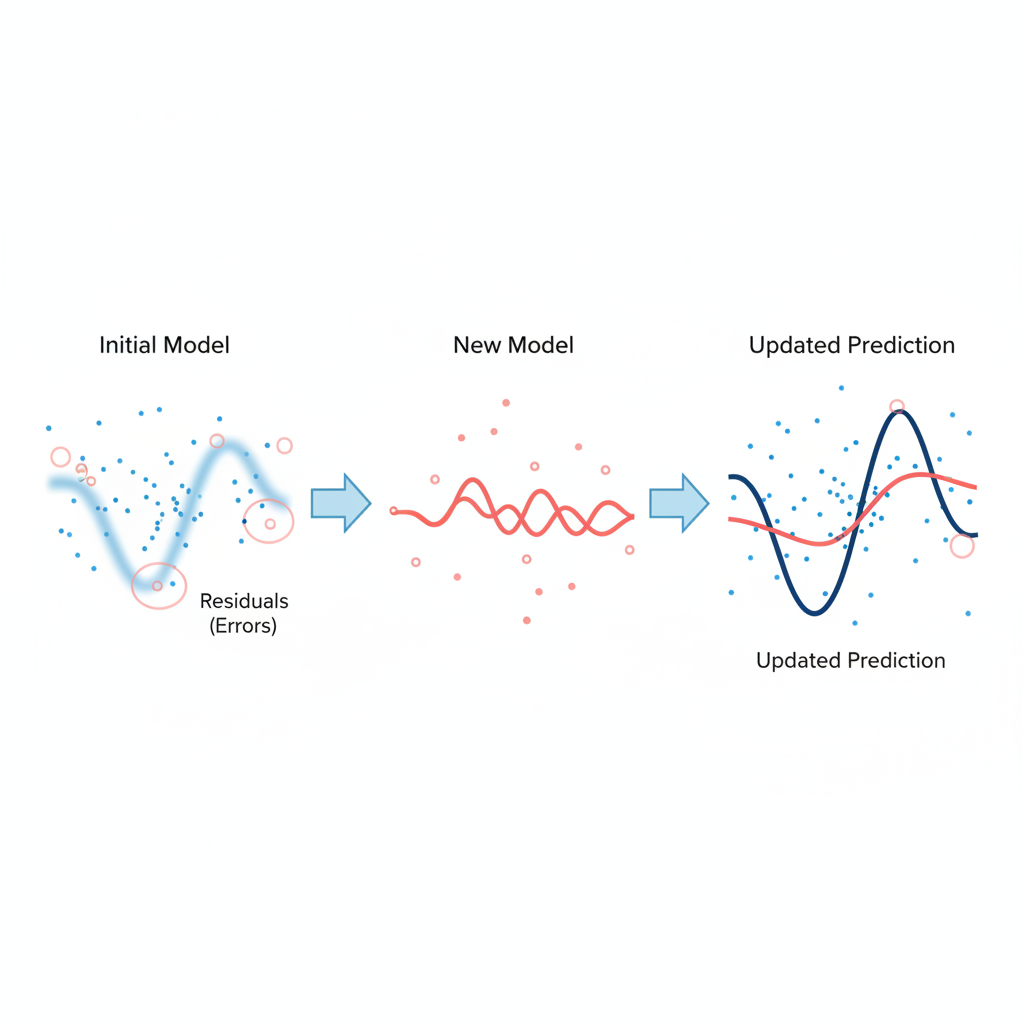
O Passo a Passo do Aprendizado Corretivo
O fluxo de treinamento segue uma receita bem definida:
- Modelo Inicial (Base): Começamos com uma previsão simples para todos os pontos de dados. Em problemas de regressão, geralmente é a média do valor alvo.
- Cálculo dos Resíduos: Calculamos os erros (resíduos) da previsão inicial. O resíduo é simplesmente
(valor real - valor previsto). - Treinamento Focado nos Erros: Um novo modelo (ex: uma árvore de decisão) é treinado. Seu objetivo não é prever o valor final, mas sim prever os resíduos da etapa anterior.
- Atualização da Previsão: A previsão do novo modelo é somada à previsão acumulada, ponderada por uma taxa de aprendizado (learning rate). Esse fator evita que cada modelo corrija os erros de forma muito agressiva, garantindo um aprendizado mais estável.
- Repetição: O processo se repete. Calculamos os novos resíduos (baseados na previsão atualizada) e treinamos um novo modelo para corrigi-los, continuando até atingir o número de modelos definido ou a performance parar de melhorar.
E Onde Entra o "Gradiente"?
A palavra "Gradiente" não está no nome por acaso. Ela se refere ao Gradiente Descendente, um famoso algoritmo de otimização. De forma simplificada, o Gradient Boosting usa essa técnica para minimizar a função de perda (que mede o quão ruim são os erros do modelo). A cada passo, os resíduos que o novo modelo tenta prever são, na verdade, uma aproximação do gradiente negativo da função de perda. Treinar um modelo para "seguir" esses resíduos é análogo a dar um passo na direção que mais rapidamente reduz o erro geral.
Prós e Contras: Quando Usar o Gradient Boosting?
Como toda ferramenta poderosa, o Gradient Boosting tem seus pontos fortes e fracos.
Vantagens
- Alta Precisão: É consistentemente um dos algoritmos com melhor performance para dados tabulares (planilhas, bancos de dados).
- Flexibilidade: Pode ser usado para tarefas de regressão, classificação e ranqueamento, além de permitir o uso de diferentes funções de perda personalizadas.
- Robustez: Implementações modernas como XGBoost e LightGBM lidam bem com dados faltantes nativamente.
Desvantagens
- Sensibilidade a Hiperparâmetros: Requer um ajuste cuidadoso de parâmetros como a taxa de aprendizado e o número de árvores para evitar overfitting.
- Custo Computacional: O treinamento é sequencial, o que significa que não pode ser facilmente paralelizado como o Random Forest. Isso pode torná-lo lento em datasets muito grandes.
- Propenso a Overfitting: Se o número de árvores for muito alto ou os modelos individuais forem muito complexos, o algoritmo pode "memorizar" os dados de treino e ter um desempenho ruim em dados novos.
Colocando a Mão na Massa: Ferramentas e Código
O Gradient Boosting é tão popular que surgiram diversas bibliotecas otimizadas. As mais famosas são XGBoost (padrão-ouro em competições), LightGBM (conhecido pela velocidade) e CatBoost (excelente para lidar com variáveis categóricas). Para começar, a implementação do Scikit-learn é perfeita.
Exemplo Prático com Scikit-learn
Veja como é simples implementar um classificador com Gradient Boosting em Python:
# Importando as bibliotecas necessárias
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score
# Criando um conjunto de dados sintético
X, y = make_classification(n_samples=1000, n_features=20, n_informative=10, random_state=42)
# Dividindo os dados em treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Criando e treinando o modelo de Gradient Boosting
gbc = GradientBoostingClassifier(
n_estimators=100, # Número de árvores (modelos fracos)
learning_rate=0.1, # Peso da correção de cada árvore
max_depth=3, # Profundidade máxima de cada árvore para evitar overfitting
random_state=42
)
gbc.fit(X_train, y_train)
# Fazendo previsões e avaliando a acurácia
predictions = gbc.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f"Acurácia do modelo: {accuracy:.4f}")
A Chave do Sucesso: Ajustando os Hiperparâmetros
O desempenho do seu modelo depende criticamente do ajuste de hiperparâmetros. Os mais importantes são:
Ajustar esses valores é um equilíbrio entre viés e variância para encontrar o ponto ótimo para o seu problema.
-n_estimators: O número de modelos sequenciais a serem treinados. Muitos podem causar overfitting.
-learning_rate: Controla o peso da contribuição de cada árvore. Valores menores exigem mais árvores, mas geralmente levam a melhores resultados.
-max_depth: Limita a complexidade de cada árvore de decisão, sendo uma das principais formas de combater o overfitting.
Conclusão: Uma Ferramenta Essencial no seu Arsenal
O Gradient Boosting deixou de ser apenas um "segredo" de competidores de Kaggle para se tornar uma ferramenta fundamental na indústria. Sua capacidade de construir modelos de alta precisão de forma incremental o torna a escolha ideal para uma vasta gama de problemas, desde detecção de fraudes financeiras e previsão de rotatividade de clientes até sistemas de recomendação e diagnósticos médicos.
Agora que você entende a lógica por trás dessa técnica poderosa, o próximo passo é experimentar. Use-a em seus projetos, ajuste seus parâmetros e veja o impacto que ela pode ter nos seus resultados!




0 Comentários