

Seu Modelo de IA é Confiável? A Importância da Validação
Imagine um atleta de elite que pulveriza recordes nos treinos, mas falha drasticamente no dia da competição oficial. No universo da Inteligência Artificial, esse cenário não é apenas comum — é um risco operacional e financeiro. Acontece quando um modelo, brilhante em ambiente de laboratório, torna-se inútil ou até prejudicial no mundo real. A validação é a disciplina que impede essa catástrofe.
Validar um modelo de IA vai além de uma etapa técnica no checklist de um cientista de dados; é o teste de fogo que determina se a solução é robusta, generalizável e pronta para gerar valor real. Sem um processo de validação rigoroso, estamos apenas construindo uma sofisticada ilusão de inteligência.

O Que é Validação e Por Que Ela é Inegociável?
Em essência, validação é o processo de avaliar o desempenho de um modelo de Machine Learning em um conjunto de dados que ele nunca viu. O objetivo é testar sua capacidade de generalização: a habilidade de aplicar o que aprendeu durante o treino para fazer previsões precisas em cenários novos e desconhecidos.
A falta de validação adequada leva ao problema mais traiçoeiro da área: o overfitting (superajuste). Um modelo com overfitting é como um sistema que "decorou" as respostas dos dados de treino em vez de "aprender" os padrões subjacentes. Ele acerta tudo que já viu, mas falha miseravelmente ao se deparar com um dado novo. No mundo dos negócios, isso se traduz em um modelo de previsão de vendas que acerta o passado com 100% de precisão, mas erra catastroficamente a projeção do próximo trimestre.
A Estratégia Fundamental: A Divisão dos Dados
A abordagem mais consolidada para validar um modelo é a divisão estratégica do conjunto de dados em três subconjuntos. Cada um tem um papel crucial e insubstituível no ciclo de vida do projeto.
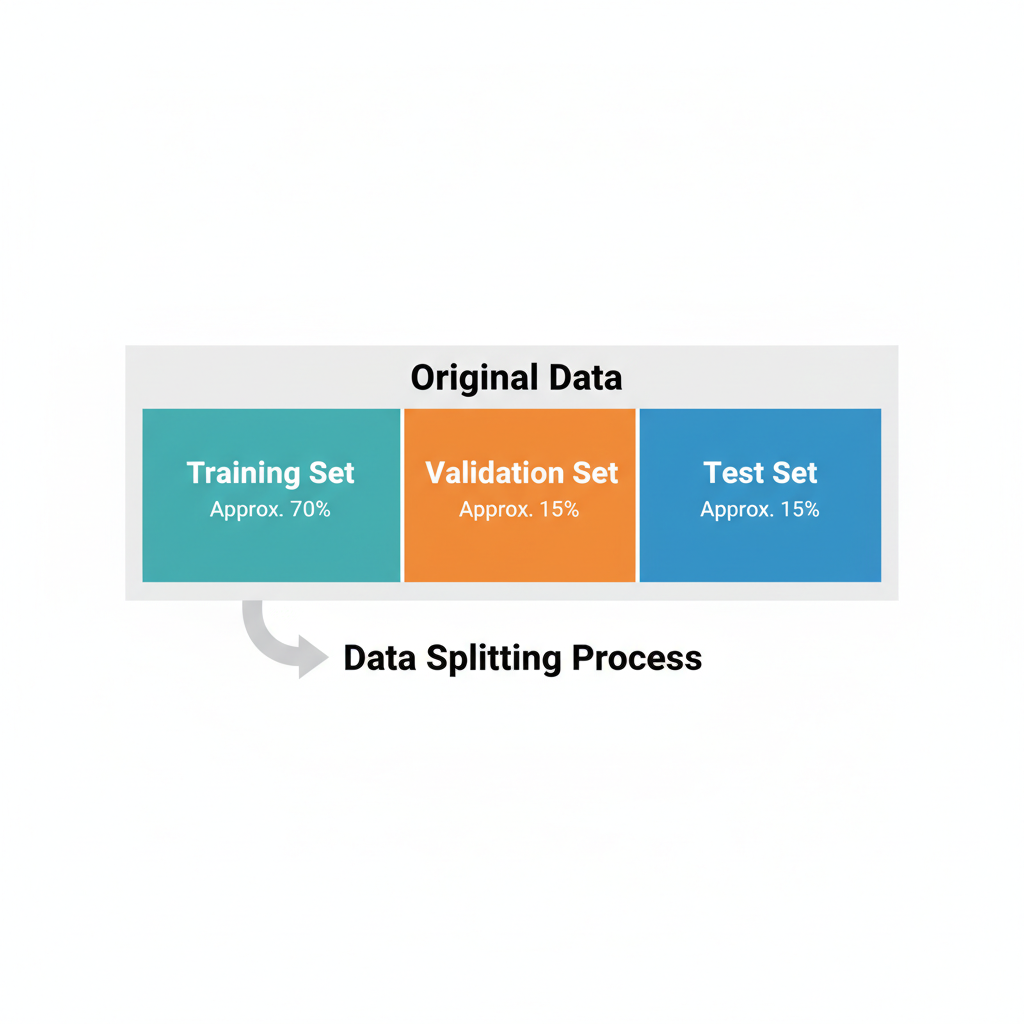
- Conjunto de Treino (Training Set): A maior fatia dos dados (tipicamente 70-80%). É aqui que o modelo aprende os padrões, as relações e as nuances, ajustando seus parâmetros internos para minimizar os erros.
- Conjunto de Validação (Validation Set): Uma porção menor (10-15%) usada como um "campo de provas" durante o desenvolvimento. Com ele, ajustamos os hiperparâmetros do modelo (como a complexidade ou a taxa de aprendizado) e escolhemos a arquitetura que melhor generaliza, sem queimar a largada usando os dados de teste.
- Conjunto de Teste (Test Set): A joia da coroa (10-15%), mantida "cega" ao modelo durante todo o processo. É o juiz final, usado uma única vez para dar o veredito imparcial sobre a performance do modelo campeão em um cenário completamente novo.
A regra de ouro do Machine Learning: o conjunto de teste é sagrado. Usá-lo para tomar qualquer decisão de modelagem invalida seus resultados e gera uma falsa sensação de segurança. – Um Mantra em Ciência de Dados
Indo Além do Básico: Validação Cruzada (Cross-Validation)
Mas e quando seu conjunto de dados não é vasto? Sacrificar 20-30% dos dados para validação e teste pode ser um luxo. Para esses cenários, a Validação Cruzada (Cross-Validation) surge como uma estratégia mais inteligente e robusta. A abordagem mais popular é a K-Fold Cross-Validation:
- O conjunto de dados de treino é particionado em 'k' subconjuntos de tamanho igual (os "folds").
- O processo se repete 'k' vezes. A cada iteração, um fold é separado para ser o conjunto de validação, enquanto os 'k-1' folds restantes são usados para treino.
- A métrica de desempenho final é a média dos resultados obtidos nas 'k' iterações, oferecendo uma estimativa muito mais estável da performance do modelo.
Essa técnica garante que cada amostra de dado seja usada tanto para treino quanto para validação, maximizando o aproveitamento dos dados e reduzindo a variância na avaliação do modelo.
Mãos à Obra: Validando na Prática com Python
A teoria é fundamental, mas a prática é onde o valor é criado. Felizmente, o ecossistema Python, com a biblioteca Scikit-learn, transforma esses conceitos em implementações diretas e eficientes.
Exemplo 1: Divisão Simples com train_test_split
Veja como é simples segmentar os dados para treino e teste, a primeira linha de defesa contra o overfitting.
# Importando a função essencial do Scikit-learn
from sklearn.model_selection import train_test_split
# Assumindo que 'X' são suas features e 'y' são seus alvos
# X, y = carregar_seus_dados()
# Dividindo os dados: 80% para treino, 20% para teste
# O 'random_state' garante que a divisão seja reprodutível
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# O modelo será treinado APENAS com X_train e y_train
# model.fit(X_train, y_train)
# A avaliação final e imparcial é feita com o conjunto de teste
# score = model.score(X_test, y_test)
print(f"Tamanho do conjunto de treino: {X_train.shape[0]} amostras")
print(f"Tamanho do conjunto de teste: {X_test.shape[0]} amostras")Exemplo 2: Robustez com Validação Cruzada K-Fold
Para uma avaliação mais confiável, especialmente com dados limitados, a validação cruzada é o caminho.
# Importando as ferramentas necessárias e um modelo de exemplo
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC # Usando um classificador de exemplo
# Assumindo que 'X' e 'y' contêm todos os seus dados
# model = SVC(kernel='linear', C=1)
# Executando a validação cruzada com 5 folds
# 'cv=5' significa que o processo de treino/validação será repetido 5 vezes
scores = cross_val_score(model, X, y, cv=5)
print(f"Acurácias em cada um dos 5 folds: {scores}")
print(f"Acurácia média: {scores.mean():.2f}")
print(f"Desvio Padrão da acurácia: {scores.std():.2f}") # Indica a consistência do modeloConclusão: De Modelo Promissor a Solução Confiável
Ignorar a validação é como lançar um navio ao mar sem nunca tê-lo testado na água. O processo transcende a mera verificação técnica; é a ponte que conecta um algoritmo promissor a uma solução de negócio robusta e confiável, capaz de entregar resultados consistentes no ambiente dinâmico do mundo real.
Ao investir tempo e rigor na validação, você não está apenas testando um modelo. Você está mitigando riscos, construindo confiança e garantindo que sua solução de IA se torne um ativo que gera valor real, de forma consistente e previsível.





0 Comentários