

Você já imaginou se pudesse combinar a opinião de vários especialistas para tomar uma decisão mais acertada?

No universo da Inteligência Artificial, essa ideia não é apenas uma metáfora, mas a base de um dos algoritmos mais poderosos e populares: o Random Forest (ou Floresta Aleatória).
Se você está iniciando sua jornada em Machine Learning, já deve ter encontrado as Árvores de Decisão. Elas são intuitivas e eficazes, mas possuem uma vulnerabilidade: sozinhas, podem se especializar demais nos dados de treino e falhar ao analisar informações novas. Esse fenômeno é conhecido como overfitting.
É aqui que a genialidade do Random Forest se revela. Em vez de depender de uma única árvore, ele cultiva uma "floresta" inteira e orquestra um debate entre elas. A decisão final é tomada por consenso, resultando em um modelo preditivo muito mais preciso e confiável. Vamos explorar como essa "sabedoria da multidão" digital funciona na prática.
O que é Random Forest, afinal?
Random Forest é um algoritmo de aprendizado de máquina supervisionado que se enquadra na técnica de Ensemble Learning (Aprendizagem de Conjunto). O princípio do ensemble é elegantemente simples: a combinação de vários modelos medianos pode gerar um modelo final extraordinariamente forte.
Pense nele como um comitê de especialistas. Cada especialista (uma Árvore de Decisão) analisa o problema de uma perspectiva ligeiramente diferente. Sozinho, um especialista pode ter seus vieses, mas o veredito coletivo tende a anular os erros individuais. Essa versatilidade permite que o Random Forest seja aplicado tanto em tarefas de classificação (prever uma categoria, como "fraude" ou "não fraude") quanto de regressão (prever um valor contínuo, como o preço de um imóvel).
Os Segredos da Floresta: Como o Algoritmo Funciona?
A construção da floresta é um processo engenhoso que se apoia em dois pilares: aleatoriedade e colaboração. O objetivo é garantir que cada árvore seja única, promovendo a diversidade de "opiniões" para que os erros individuais não se propaguem.
1. Bootstrapping: Criando Múltiplas Visões dos Dados
Imagine um conjunto de dados com 1.000 amostras. Para treinar a primeira árvore, o algoritmo não utiliza o conjunto inteiro. Em vez disso, ele cria um novo subconjunto selecionando 1.000 amostras aleatoriamente, com reposição. Isso significa que um mesmo dado pode ser escolhido mais de uma vez, enquanto outros podem ficar de fora.
Esse processo, chamado bootstrapping, é repetido para cada árvore, garantindo que cada uma seja treinada com uma "visão" ligeiramente diferente dos dados originais, o que aumenta a independência entre elas.
2. Aleatoriedade de Atributos: Forçando a Diversidade
Aqui entra o segundo toque de aleatoriedade. Ao construir cada nó de uma árvore, o algoritmo não avalia todas as variáveis (features) disponíveis para decidir a melhor divisão. Ele seleciona apenas um subconjunto aleatório delas.
Por exemplo, se seus dados possuem 10 features, cada ponto de decisão da árvore pode ser forçado a escolher a melhor divisão usando apenas 3 ou 4. Essa restrição impede que uma única feature muito dominante monopolize as decisões de todas as árvores, incentivando o modelo a encontrar padrões diferentes e complementares.
3. A Decisão Final: O Poder da Votação
Com a floresta treinada, o modelo está pronto para fazer previsões. Um novo dado é apresentado e percorre todas as árvores simultaneamente. Cada árvore emite seu próprio veredito.
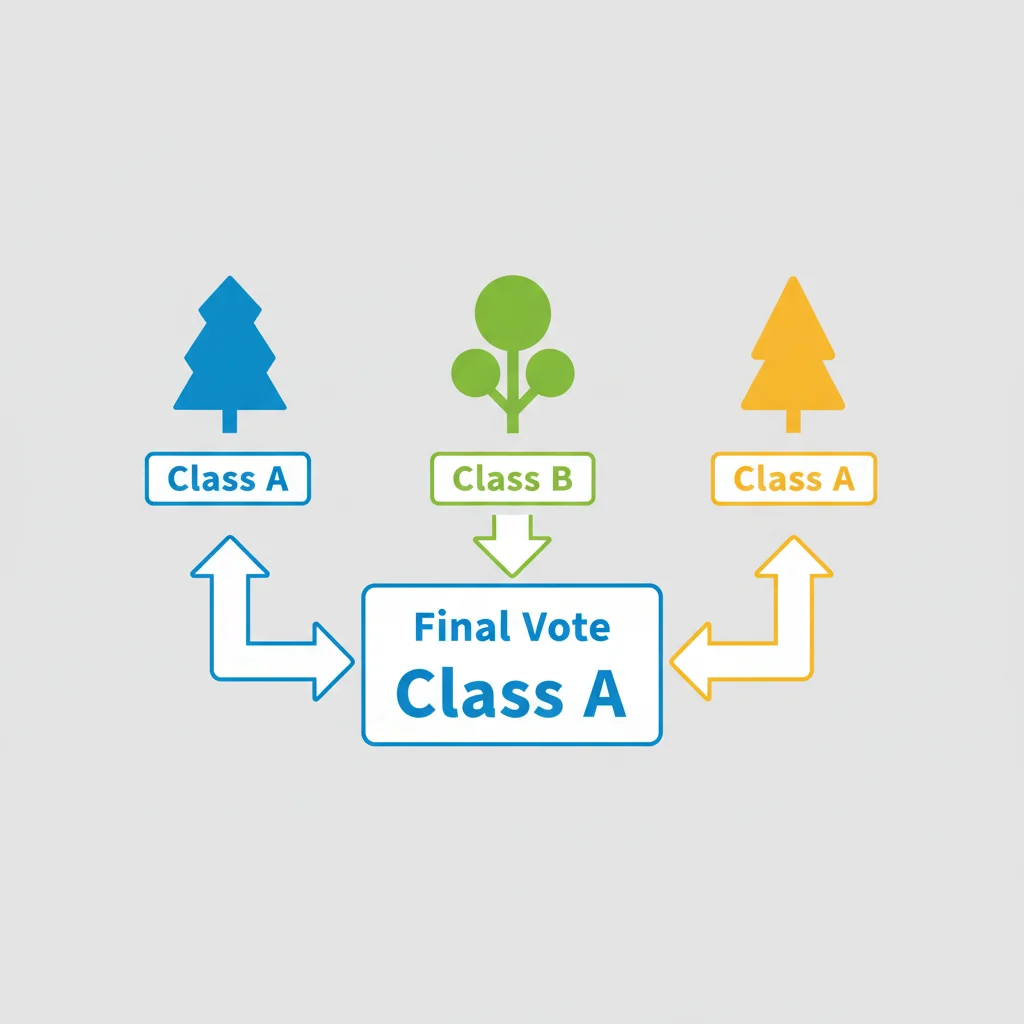
A decisão final é tomada de forma democrática:
- Para classificação: A classe que recebe o maior número de votos é a escolhida. Se 80 árvores preveem "spam" e 20 preveem "não spam", a previsão final será "spam".
- Para regressão: O resultado final é a média de todas as previsões numéricas feitas pelas árvores individuais.
Exemplo Prático com Python e Scikit-Learn
Vamos colocar a mão na massa! Implementar um Random Forest é surpreendentemente direto com bibliotecas como o Scikit-Learn. Abaixo, um exemplo clássico usando o dataset Iris para classificar espécies de flores:
# Importando as bibliotecas essenciais
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.Datasets import load_iris
# Carregando o conjunto de dados Iris (um clássico para classificação)
iris = load_iris()
X = iris.data # Características das flores (features)
y = iris.target # Espécies (alvo)
# Dividindo os dados em conjuntos de treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Instanciando o classificador Random Forest com 100 árvores
# n_estimators define o número de árvores na floresta
clf = RandomForestClassifier(n_estimators=100, random_state=42)
# Treinando o modelo com os dados de treino
clf.fit(X_train, y_train)
# Realizando previsões com o conjunto de teste
y_pred = clf.predict(X_test)
# Avaliando a acurácia do modelo
acuracia = accuracy_score(y_test, y_pred)
print(f"Acurácia do modelo: {acuracia * 100:.2f}%")
# Saída esperada: Acurácia do modelo: 100.00%
Conclusão: O Poder da Colaboração
O Random Forest é uma ferramenta fundamental no arsenal de qualquer entusiasta ou profissional de Machine Learning. Sua popularidade não é por acaso: ele oferece alta precisão, é robusto contra overfitting e funciona bem sem a necessidade de uma calibração exaustiva de parâmetros.
Ao compreender como a combinação estratégica de múltiplos modelos simples gera uma inteligência coletiva poderosa, você dá um passo crucial para construir soluções de IA mais sofisticadas, confiáveis e preparadas para os desafios do mundo real.





0 Comentários