

O que é Aprendizagem Não Supervisionada?
Imagine receber uma caixa gigante cheia de peças de LEGO de todos os tipos, cores e tamanhos, mas sem nenhum manual de instruções. Sua tarefa é organizar tudo. O que você faria? Provavelmente começaria a agrupar as peças por cor, depois por formato, criando seus próprios conjuntos lógicos. Parabéns, você acabou de realizar uma tarefa de aprendizagem não supervisionada!
Diferente da aprendizagem supervisionada, onde o algoritmo de Inteligência Artificial aprende com dados previamente rotulados (como fotos de cães com a etiqueta "cão"), a aprendizagem não supervisionada trabalha com dados brutos, sem rótulos. O objetivo não é prever um resultado específico, mas sim explorar os dados e descobrir padrões, estruturas e relações ocultas por conta própria.
Como Funciona na Prática?
O algoritmo atua como um detetive, analisando um grande volume de informações e procurando por pistas que conectem os pontos. Ele não sabe o que está procurando, mas consegue identificar semelhanças e anomalias. A "mágica" está nos algoritmos projetados para encontrar essas estruturas inerentes nos dados. Vamos conhecer os principais tipos.
Principais Tipos e Algoritmos
Existem várias abordagens na aprendizagem não supervisionada, mas três se destacam para quem está começando:
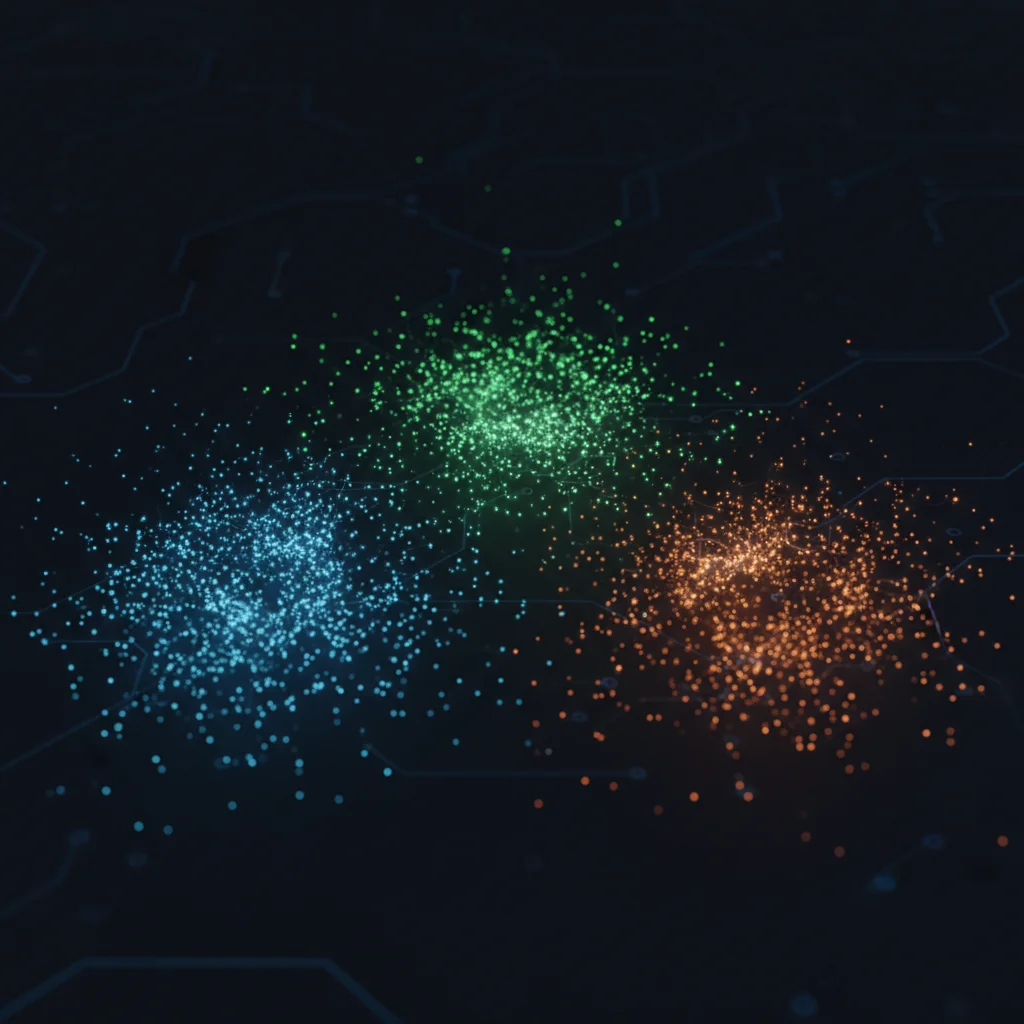
1. Clustering (Agrupamento)
O clustering é talvez o tipo mais intuitivo. Seu objetivo é agrupar dados semelhantes em "clusters" ou conjuntos. Itens dentro de um mesmo cluster são muito parecidos entre si e bem diferentes dos itens de outros clusters. Uma aplicação clássica é a segmentação de clientes, onde uma empresa pode agrupar seus clientes com base em comportamento de compra para criar campanhas de marketing personalizadas.
Principal Algoritmo: K-Means.
2. Associação
Aqui, o objetivo é descobrir regras e relações entre variáveis em grandes conjuntos de dados. A famosa "análise de cesta de compras" é o melhor exemplo. Um supermercado pode descobrir que clientes que compram pão também tendem a comprar leite. Essa informação é ouro para estratégias de posicionamento de produtos e promoções. Os sistemas de recomendação da Netflix e Amazon usam fortemente regras de associação.
Principal Algoritmo: Apriori.

3. Redução de Dimensionalidade
Às vezes, temos dados com centenas ou milhares de variáveis (ou "dimensões"). Isso pode tornar a análise computacionalmente cara e complexa. A redução de dimensionalidade simplifica os dados, diminuindo o número de variáveis, mas tentando preservar ao máximo a informação importante. É como criar um resumo conciso de um livro muito longo sem perder a história principal.
Principal Algoritmo: PCA (Principal Component Analysis).
Conclusão: O Poder dos Dados Brutos
A aprendizagem não supervisionada é uma área fascinante e poderosa da inteligência artificial. Ela nos permite extrair insights valiosos de oceanos de dados brutos e não estruturados, que compõem a maior parte dos dados gerados no mundo hoje. Desde a detecção de fraudes financeiras até a organização de documentos e a descoberta de novos segmentos de mercado, suas aplicações são vastas e continuam a crescer. Para qualquer iniciante em IA, entender seus fundamentos é um passo crucial para desvendar o verdadeiro potencial dos dados.





0 Comentários