

O que é Treinamento Supervisionado? Um Guia Completo para Iniciantes em IA
Imagine que você está aprendendo a identificar frutas. Um supervisor mostra uma maçã e diz: "Isto é uma maçã". Em seguida, uma banana: "Isto é uma banana". Após analisar centenas de exemplos, seu cérebro aprende a reconhecer os padrões — cor, formato, textura — de cada uma. Logo, você consegue identificar uma fruta que nunca viu antes. O Treinamento Supervisionado em Inteligência Artificial funciona exatamente assim.
É a abordagem mais comum e fundamental do Machine Learning (Aprendizado de Máquina), na qual ensinamos um algoritmo fornecendo um conjunto de dados que já contém as respostas corretas. Esses dados são chamados de dados rotulados. O objetivo é que o modelo aprenda a mapear a relação entre os dados de entrada (as características da fruta) e os rótulos de saída (o nome da fruta) para, no futuro, fazer previsões precisas sobre dados novos e desconhecidos.
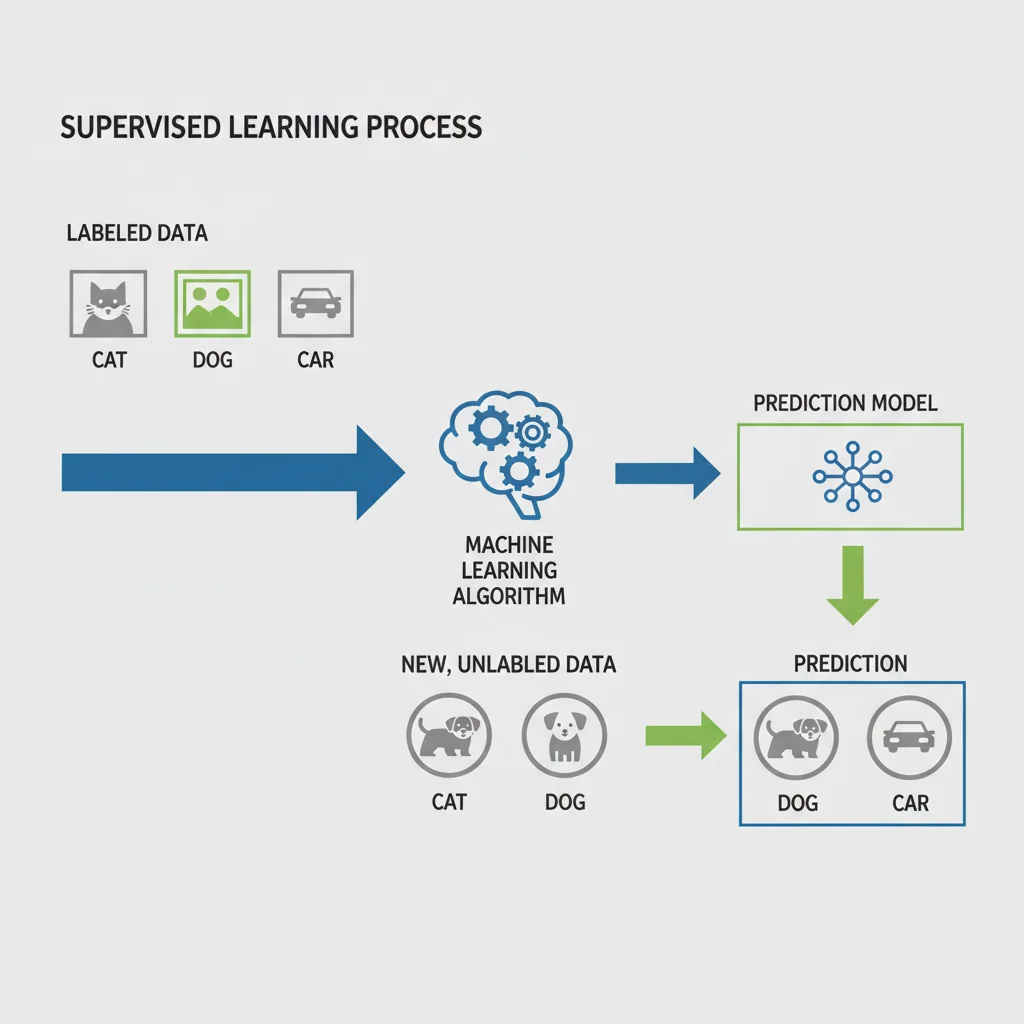
Como Funciona o Processo na Prática?
O processo de treinamento supervisionado pode ser dividido em quatro etapas-chave:
- Coleta de Dados Rotulados: A primeira e mais crucial etapa. Precisamos de um grande volume de dados onde cada exemplo tem uma etiqueta ou "resposta" correta. Por exemplo, um banco de dados com milhares de e-mails, cada um rotulado como 'spam' ou 'não spam'.
- Divisão dos Dados: Este conjunto é normalmente dividido em duas partes: um conjunto de treinamento (a maior parte, usada para ensinar o modelo) e um conjunto de teste (uma parte menor, usada para avaliar o desempenho do modelo, como se fosse uma prova final).
- Treinamento do Algoritmo: O algoritmo de machine learning processa o conjunto de treinamento, analisando as características dos dados de entrada e ajustando seus parâmetros internos para mapear corretamente as entradas às saídas correspondentes. Ele busca os padrões que conectam os dados à sua classificação.
- Avaliação do Modelo: Após o treinamento, usamos o conjunto de teste (que o modelo nunca viu antes) para verificar sua precisão. Se o modelo consegue classificar corretamente os e-mails do conjunto de teste, consideramos que ele aprendeu com sucesso e está pronto para ser usado.
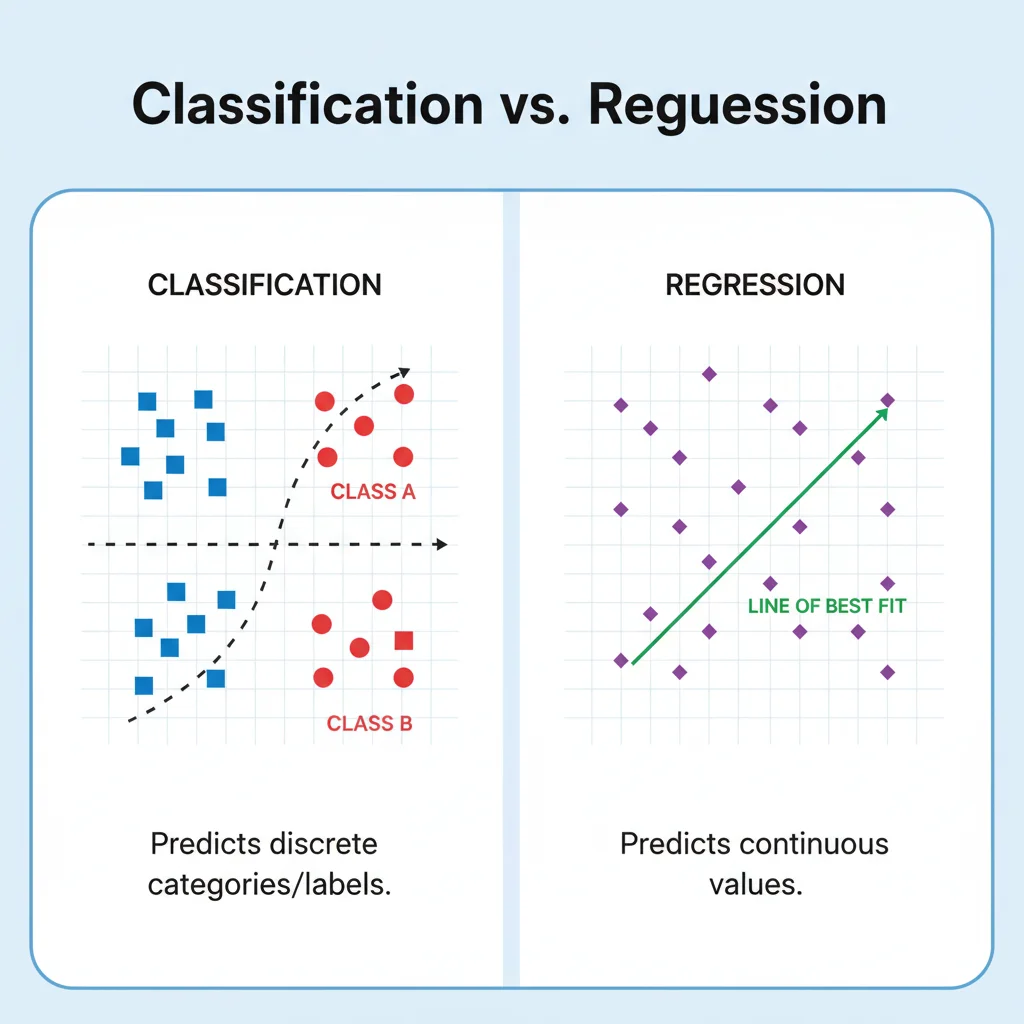
Principais Tipos de Problemas Resolvidos
O treinamento supervisionado é excelente para resolver dois tipos principais de problemas: classificação e regressão.
Classificação: Prevendo Categorias
O objetivo aqui é prever uma categoria discreta, como responder a uma pergunta de múltipla escolha. O modelo aprende a classificar os dados em duas ou mais classes distintas. Algoritmos populares para classificação incluem as Máquinas de Vetores de Suporte (SVM) e as poderosas Redes Neurais, que são a base para tarefas complexas como reconhecimento de imagens.
- Exemplo 1: Filtro de spam. O modelo classifica um e-mail como "spam" ou "não spam".
- Exemplo 2: Diagnóstico médico. Com base em exames, o modelo pode classificar um tumor como "benigno" ou "maligno".
- Exemplo 3: Reconhecimento de imagem. Identificar se uma foto contém um "cachorro", "gato" ou "pássaro".
Regressão: Prevendo Valores Numéricos
Neste caso, o objetivo é prever um valor numérico contínuo. Em vez de escolher uma categoria, o modelo tenta estimar um número. Um dos algoritmos mais clássicos e eficazes para isso é a Regressão Linear, usada para modelar a relação entre variáveis, como prever o preço de um imóvel com base em sua área e localização.
- Exemplo 1: Previsão de preços de imóveis. Com base nas características de uma casa (área, quartos), o modelo prevê seu valor de venda.
- Exemplo 2: Previsão do tempo. Estimar a temperatura máxima de amanhã com base em dados históricos.
- Exemplo 3: Estimativa de tempo de entrega. Prever em quantos minutos um pedido de comida chegará.
O Pilar do Aprendizado de Máquina
O Treinamento Supervisionado é a espinha dorsal de muitas aplicações de IA que usamos todos os dias, desde a recomendação de filmes em serviços de streaming até o Reconhecimento Facial que desbloqueia nossos celulares. Sua principal força está na capacidade de produzir modelos altamente precisos quando dispomos de dados rotulados de boa qualidade.
No entanto, seu maior desafio é justamente a necessidade de obter esses dados, um processo que pode ser caro e demorado. Ainda assim, entender este conceito é o primeiro e mais importante passo para qualquer pessoa que deseja desvendar o fascinante mundo da Inteligência Artificial.
O que Aprender a Seguir? Próximos Passos
Dominar o Treinamento Supervisionado é um marco fundamental. Mas e quando não temos dados rotulados? Aí entra outra área fascinante do Machine Learning. Seu próximo passo na jornada é entender seu oposto complementar.
- Explore o Treinamento Não Supervisionado: Descubra como os algoritmos encontram padrões e estruturas ocultas em dados sem rótulos.





0 Comentários