

O que são Pipelines de Dados: O Guia Essencial para Iniciantes
Imagine uma cidade que precisa de água limpa. A água bruta é coletada de rios (as fontes), passa por uma estação onde é filtrada e purificada (o processamento) e, finalmente, é distribuída por uma rede de canos até as casas (o destino). Um pipeline de dados opera com a mesma lógica fundamental, mas para o ativo mais valioso do século XXI: a informação.
De forma simples, um pipeline de dados é uma série de processos automatizados que move dados de um sistema de origem para um destino. No entanto, sua função vai muito além do transporte. Ele orquestra a coleta de dados brutos, os transforma em um formato útil e confiável e os entrega prontos para análise, alimentando desde dashboards estratégicos até complexos modelos de inteligência artificial.
Por que Pipelines de Dados são a Espinha Dorsal do Negócio Moderno?
Sem uma infraestrutura de dados organizada, as informações seriam como água suja e estagnada: abundante, mas inútil. Pipelines de dados garantem que os dados certos cheguem ao lugar certo, na hora certa e no formato correto, servindo como alicerce para três pilares estratégicos:
Tomada de Decisão Baseada em Dados
Empresas orientadas a dados (data-driven) utilizam pipelines para alimentar dashboards de Business Intelligence (BI) e relatórios analíticos. Com dados atualizados e confiáveis, gestores abandonam a intuição e tomam decisões estratégicas baseadas em evidências, otimizando operações e identificando novas oportunidades de mercado.
Inovação com Inteligência Artificial e Machine Learning
Modelos de Inteligência Artificial e Machine Learning são famintos por dados de alta qualidade. Os pipelines funcionam como as artérias que fornecem volumes massivos de informações limpas e estruturadas para o treinamento desses modelos, viabilizando desde sistemas de recomendação personalizados até diagnósticos preditivos.
Criação de uma Fonte Única da Verdade
Ao centralizar o processamento e a validação, os pipelines estabelecem uma "fonte única da verdade" (Single Source of Truth). Isso garante que todos na organização — do marketing às finanças — trabalhem com os mesmos números, eliminando inconsistências, reduzindo erros e construindo uma cultura de confiança nos dados.
Anatomia de um Pipeline de Dados: O Clássico ETL
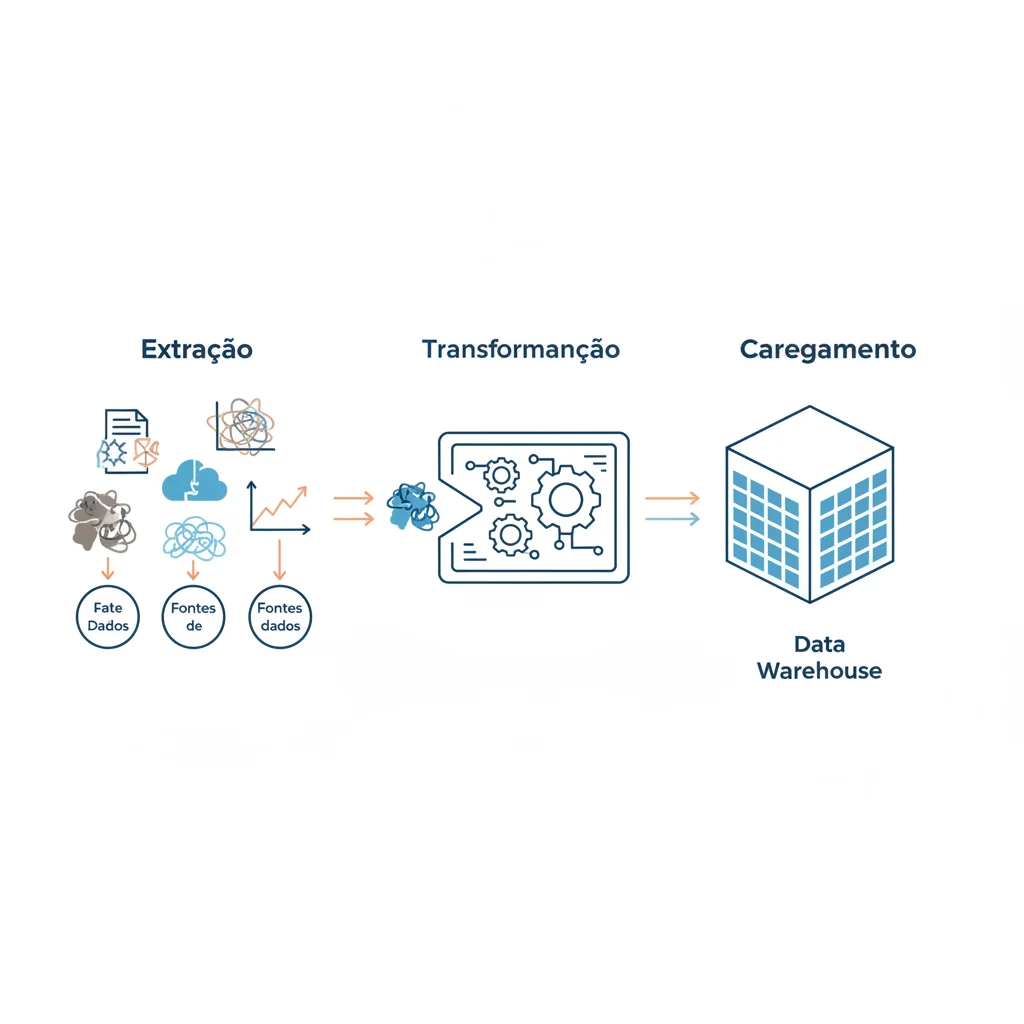
A arquitetura mais tradicional para um pipeline de dados é o ETL (Extract, Transform, Load), um acrônimo para Extrair, Transformar e Carregar. Vamos detalhar cada etapa.
1. Extração (Extract): O Ponto de Partida
Nesta fase, os dados são coletados de suas fontes originais, que podem ser extremamente diversas: bancos de dados de um site de E-commerce, APIs de redes sociais, planilhas, sensores de IoT ou logs de aplicação. O desafio é conectar-se a esses sistemas e extrair os dados brutos de forma eficiente e sem sobrecarregar as fontes.
2. Transformação (Transform): A Mágica Acontece Aqui
Os dados brutos raramente estão prontos para análise. A etapa de transformação é onde eles são limpos, padronizados, enriquecidos e modelados para atender às necessidades do negócio. Tarefas comuns incluem:
- Limpeza: Remover dados duplicados, corrigir erros de digitação e tratar valores ausentes.
- Padronização: Unificar formatos, como converter todas as datas para o padrão `AAAA-MM-DD` ou moedas para uma única referência.
- Enriquecimento: Cruzar dados de diferentes fontes para adicionar contexto, como combinar dados de vendas com informações demográficas de clientes.
- Agregação: Sumarizar dados em um nível mais alto, como calcular o total de vendas por dia ou por região.
3. Carregamento (Load): O Destino Final
Após a transformação, os dados processados e refinados são carregados em seu destino. Geralmente, trata-se de um sistema otimizado para análise, como um Data Warehouse ou um Data Lake, onde ficarão disponíveis para analistas, cientistas de dados e ferramentas de BI.
A Evolução: Entendendo a Diferença Crucial entre ETL e ELT
Com o surgimento de Data Warehouses em nuvem com poder de processamento massivo (como Google BigQuery, Amazon Redshift e Snowflake), uma nova abordagem ganhou força: ELT (Extract, Load, Transform).
A diferença, embora sutil na sigla, é transformadora na prática. No ELT, os dados brutos são primeiro carregados (Load) no Data Warehouse e só então são transformados (Transform) usando o poder computacional do próprio destino. Essa inversão oferece vantagens significativas:
- Flexibilidade: Todos os dados brutos ficam disponíveis no destino, permitindo que diferentes equipes apliquem transformações específicas para suas próprias análises, sem precisar reprocessar tudo desde a origem.
- Velocidade: A etapa de carregamento é muito mais rápida, pois não espera por transformações complexas, disponibilizando os dados quase em tempo real para exploração.
- Escalabilidade: Aproveita a capacidade elástica dos sistemas em nuvem para executar transformações complexas em grandes volumes de dados de forma eficiente.
Pipeline de Dados na Prática: O Exemplo de um E-commerce
Para tornar o conceito mais concreto, vamos imaginar um pipeline para uma loja online que deseja otimizar seu estoque e personalizar campanhas de marketing. O objetivo de negócio é claro: prever a demanda de produtos e entender a jornada de compra do cliente.
- Fontes de Dados: O pipeline se conecta a três sistemas: o banco de dados de pedidos (MySQL), os eventos de navegação no site (Google Analytics) e o sistema de gestão de estoque (ERP).
- Extração (E) e Carregamento (L): A cada hora, um processo automatizado extrai novos pedidos, cliques de usuários e os níveis de estoque atualizados. Esses dados brutos são imediatamente carregados em um Data Warehouse na nuvem, como o BigQuery, em tabelas separadas (
raw_orders,raw_clicks,raw_inventory). - Transformação (T): Utilizando comandos SQL diretamente no BigQuery, a equipe de dados executa as transformações:
- Os pedidos são cruzados com os dados de cliques para mapear a jornada do cliente, desde o primeiro acesso até a compra.
- As vendas diárias são agregadas por produto e subtraídas do estoque para calcular a "cobertura de estoque" (quantos dias de venda o estoque atual suporta).
- Os clientes são segmentados com base no histórico de compras e comportamento de navegação.
- Destino e Análise: Os dados transformados alimentam um dashboard em uma ferramenta como o Looker Studio. Agora, a gestão pode visualizar em tempo real os produtos mais vendidos por região, a taxa de conversão de campanhas e, mais importante, receber alertas automáticos sobre itens com risco de esgotamento.
Ferramentas do Ecossistema: Construindo Pipelines de Dados Robustos
Construir um pipeline resiliente exige as ferramentas certas. O ecossistema de engenharia de dados é vasto, mas as ferramentas geralmente se enquadram em algumas categorias principais:
Orquestração de Fluxos: Apache Airflow
Ferramenta open-source líder para programar, agendar e monitorar fluxos de trabalho. Com o Airflow, os pipelines são definidos como código (Python), o que oferece enorme flexibilidade, controle de versão e capacidade de gerenciar dependências complexas entre tarefas.
Streaming de Dados em Tempo Real: Apache Kafka
Enquanto o Airflow é ótimo para processos em lote (batch), o Kafka é a escolha para streaming de dados. Ele funciona como um sistema de mensagens distribuído que permite construir pipelines que processam eventos em tempo real, essencial para casos como detecção de fraudes, monitoramento de sistemas e análise de cliques.
Plataformas Gerenciadas em Nuvem
Serviços como AWS Glue, Google Cloud Dataflow e Azure Data Factory são soluções "serverless" que simplificam a criação de pipelines ETL/ELT. Eles gerenciam a infraestrutura subjacente, permitindo que as equipes se concentrem na lógica de negócio em vez de se preocuparem com servidores e escalabilidade.
Desafios Críticos na Gestão de Pipelines de Dados
Criar um pipeline é apenas o começo. Mantê-lo saudável, confiável e seguro ao longo do tempo envolve superar desafios contínuos:
Monitoramento e Observabilidade
Não basta saber se o pipeline falhou. É preciso ter observabilidade: entender por que falhou. Isso envolve monitorar a qualidade dos dados (data quality), o tempo de execução (latency) e o consumo de recursos, com sistemas de alerta proativos para notificar a equipe antes que um problema impacte o negócio.
Governança e Segurança de Dados
Garantir a segurança, privacidade (em conformidade com leis como LGPD/GDPR) e a linhagem dos dados (de onde vieram e como foram transformados) é fundamental. A governança de dados estabelece políticas sobre quem pode acessar o quê e garante a integridade da informação em todo o seu ciclo de vida.
Escalabilidade e Manutenção
O volume de dados tende a crescer exponencialmente. Um pipeline deve ser projetado para escalar de forma eficiente, lidando com picos de carga sem degradar a performance. Além disso, a manutenção contínua é crucial para corrigir bugs, otimizar processos e adaptar o pipeline a novas fontes de dados ou regras de negócio.
Conclusão: Do Dado Bruto ao Valor Estratégico
Pipelines de dados são muito mais do que um conceito técnico; eles representam a infraestrutura que viabiliza a transformação digital. São a espinha dorsal de qualquer organização que deseja evoluir da simples coleta de informações para a geração de inteligência competitiva. Ao automatizar o fluxo que transforma dados brutos em insights poderosos, eles liberam equipes para focar no que realmente importa: usar a informação para inovar e crescer. Agora que você entende os componentes, as abordagens (ETL/ELT), as ferramentas e os desafios, está pronto para dar o próximo passo no fascinante mundo da engenharia e análise de dados.





0 Comentários