

O que é Support Vector Machine (SVM)? Guia Completo com Exemplos e Código
Se você está mergulhando no universo do Machine Learning, certamente encontrará algoritmos com nomes que parecem complexos. Um dos mais poderosos e elegantes é o Support Vector Machine (SVM), ou Máquina de Vetores de Suporte. Mas não se intimide pelo nome!
A intuição por trás do SVM é brilhantemente simples. Imagine ter um gráfico com maçãs e laranjas. Sua tarefa é traçar uma linha que separe os dois grupos da melhor maneira possível. A maioria de nós desenharia essa linha bem no meio, criando a maior distância possível entre a linha e as frutas mais próximas de cada grupo. Essa é a essência do SVM: encontrar a fronteira de decisão ótima que maximiza essa "zona de segurança".
Em termos técnicos, o SVM é um algoritmo de aprendizado supervisionado, extremamente eficaz para tarefas de classificação (como identificar e-mails de spam) e também para problemas de regressão (prever um valor contínuo).
Como o SVM Encontra a Melhor Divisão?
Para dominar o SVM, precisamos entender três conceitos fundamentais que definem sua estratégia:
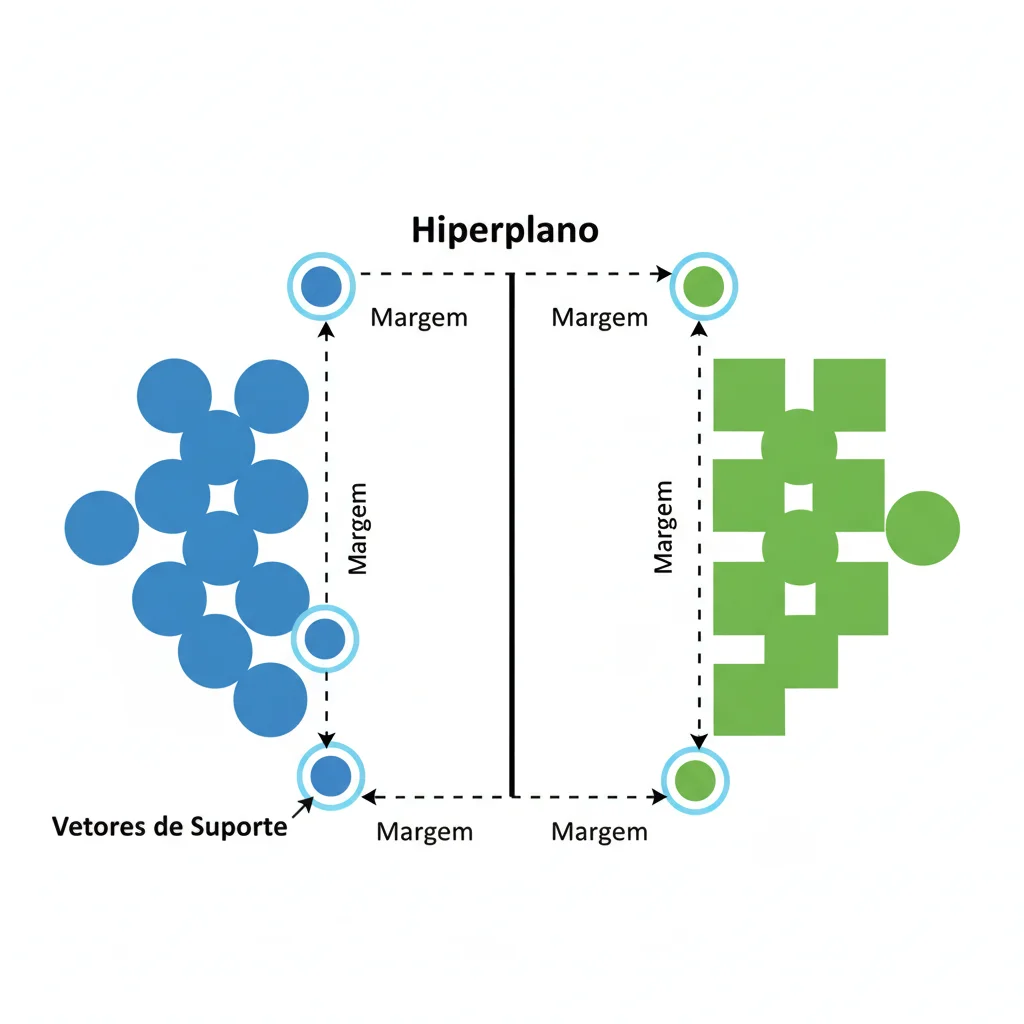
- Hiperplano: Em um gráfico de duas dimensões, o hiperplano é simplesmente a linha reta que separa os dados. Se tivéssemos três dimensões, seria um plano. Em mais dimensões, ele continua sendo a fronteira de decisão, daí o nome genérico "hiperplano".
- Margem: Esta é a "avenida" ou o espaço entre o hiperplano e os pontos de dados mais próximos de cada classe. O objetivo principal do SVM é encontrar o hiperplano que resulta na margem máxima. Uma margem mais larga geralmente leva a um modelo com melhor capacidade de generalização, ou seja, ele classifica novos dados com mais precisão.
- Vetores de Suporte: São os pontos de dados localizados nas bordas da margem. Eles são os elementos mais importantes do conjunto de treinamento, pois são eles que "suportam" e definem a posição e orientação do hiperplano. Se qualquer um desses vetores fosse movido, o hiperplano se ajustaria.
O "Truque do Kernel": Lidando com Dados Complexos
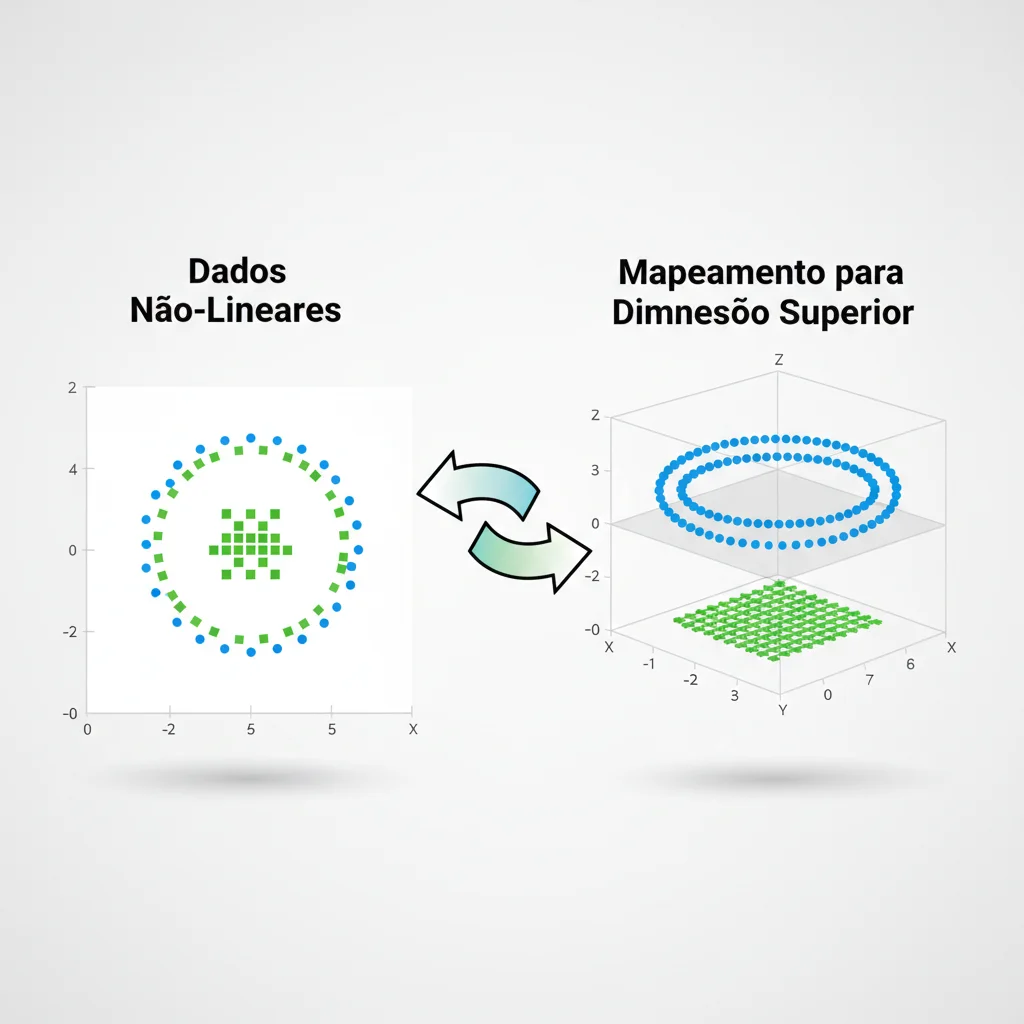
"Ok, a ideia da linha reta faz sentido. Mas e se os dados não forem linearmente separáveis?" Ótima pergunta. Imagine que as maçãs formam um anel ao redor das laranjas. Nenhuma linha reta consegue separá-las.
É aqui que o genial Truque do Kernel (Kernel Trick) entra em cena. O SVM utiliza funções matemáticas (kernels) para projetar os dados em um espaço de dimensão superior. Nesse novo espaço, os dados que antes eram inseparáveis podem se tornar perfeitamente separáveis por um hiperplano.
Pense em pontos misturados em uma folha de papel (2D). Agora, imagine que você joga esses pontos para cima. No ar (3D), você pode facilmente deslizar uma nova folha de papel (o hiperplano) entre eles. Essa é a maior força do SVM: sua capacidade de modelar relações complexas e não-lineares sem um custo computacional proibitivo.
Quando usar o SVM? Casos de Uso Práticos
O SVM não é apenas teoria; ele é a base de muitas aplicações do mundo real. Veja alguns exemplos de onde ele brilha:
- Classificação de Texto: É excelente para análise de sentimentos, categorização de notícias e, classicamente, para filtrar e-mails de spam. A alta dimensionalidade dos dados de texto (onde cada palavra pode ser uma dimensão) é um cenário onde o SVM se destaca.
- Reconhecimento de Imagens: Utilizado em tarefas como reconhecimento facial, identificação de objetos e até mesmo na classificação de dígitos manuscritos.
- Bioinformática: Na biologia computacional, o SVM ajuda a classificar proteínas e a identificar genes associados a doenças, onde os conjuntos de dados podem ser pequenos, mas com muitas características.
SVM vs. Regressão Logística: Qual Escolher?
Iniciantes frequentemente se perguntam sobre a diferença entre SVM e outro classificador popular, a Regressão Logística. Embora ambos possam resolver problemas de classificação, eles operam com filosofias diferentes.
| Característica | Support Vector Machine (SVM) | Regressão Logística |
|---|---|---|
| Objetivo Principal | Encontrar o hiperplano que maximiza a margem entre as classes. | Modelar a probabilidade de uma determinada classe. |
| Interpretação | O resultado é uma classe (ex: 1 ou -1). A interpretação probabilística não é nativa. | Fornece uma saída de probabilidade direta (ex: 70% de chance de ser spam). |
| Performance | Excelente em dados de alta dimensão e com amostras menores. Robusto contra outliers. | Funciona bem em grandes conjuntos de dados e é computacionalmente mais simples. |
| Complexidade | Pode modelar fronteiras não-lineares facilmente com o truque do kernel. | É um modelo inerentemente linear (embora possa ser estendido). |
Resumindo: Use SVM quando a clareza da fronteira de decisão for crucial e você estiver lidando com dados complexos e de alta dimensão. Opte pela Regressão Logística quando precisar de saídas probabilísticas e um modelo mais simples e interpretável.
SVM na Prática: Exemplo de Código com Python
Ver a teoria em ação é a melhor forma de aprender. Aqui está um exemplo simples de como treinar um classificador SVM usando a popular biblioteca Scikit-learn em Python.
# 1. Importar as bibliotecas necessárias
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score
# 2. Gerar dados de exemplo (2 características, 2 classes)
# Em um projeto real, você usaria seus próprios dados aqui
X, y = make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0, random_state=42)
# 3. Dividir os dados em conjuntos de treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 4. Criar e treinar o modelo SVM
# Usaremos um kernel 'linear' para este exemplo simples
clf = svm.SVC(kernel='linear')
clf.fit(X_train, y_train)
# 5. Fazer previsões no conjunto de teste
y_pred = clf.predict(X_test)
# 6. Avaliar a precisão do modelo
accuracy = accuracy_score(y_test, y_pred)
print(f"Acurácia do modelo SVM: {accuracy:.2f}")
Este código cria um conjunto de dados simples, treina um classificador SVM com um kernel linear e avalia sua precisão. Com poucas linhas, você tem um modelo funcional, demonstrando o poder das bibliotecas modernas de Machine Learning.
Conclusão: Por que o SVM é Relevante?
O Support Vector Machine é mais do que apenas outro algoritmo. É uma ferramenta robusta e matematicamente elegante que oferece excelente desempenho em diversos cenários, especialmente com dados complexos e de alta dimensão. Suas principais vantagens são:
- Eficaz em espaços de alta dimensão, mesmo quando o número de dimensões é maior que o número de amostras.
- Eficiente em memória, pois usa apenas os vetores de suporte para construir a fronteira de decisão.
- Extremamente versátil graças aos diferentes tipos de kernels que podem ser aplicados.
Embora possa ser mais lento em conjuntos de dados massivos em comparação com outros algoritmos, o SVM continua sendo um pilar no campo do Machine Learning. Entendê-lo não é apenas um exercício acadêmico; é adquirir uma ferramenta poderosa para construir modelos de classificação mais precisos e robustos.





0 Comentários